

易观分析发布《2025年AI产业发展十大趋势》报告,后续将针对十大趋势分别进行解析:

趋势之二:多模态模型能力持续升级,朝向多模态理解和生成的统一发展
当前自然语言、音频、视频等多个模态的理解与生成能力均提升显著,在模型创新、跨模态能力提升、性能优化上有进展,并涌现出不少基于多模态模型的应用和探索。目前多模态大模型主要有两种思路,具体如下:

具体来说,当前多模态模型的进展如下:
l新模型不断涌现
研究机构和企业不断推出性能强大的多模态模型,例如智源人工智能研究院 Emu3,是全球首个原生多模态世界模型,通过自回归技术结合图像、文本和视频三种模态,在图像生成、视觉语言理解和生成方面表现出色。
l训练方法优化
训练方式不断创新,例如新的联合训练策略,即在训练过程中先固定大语言模型的权重参数,对图像编码器和桥接组件进行初步训练,然后再对整个模型进行整体训练,这种分阶段的训练方式有助于提高模型的性能和效率。
l跨模态交互能力增强
能够更好地理解和关联不同模态之间的信息,实现更精准的跨模态交互和转换,例如,可以根据文本描述生成高质量的图像或视频,也可以理解图像或视频内容并生成相关的文本描述,并且在语义一致性方面有了很大提升。
l性能提升
计算效率提高,多模态模型计算速度加快、响应时间缩短,可快速处理分析数据满足实时需求。同时,模型结构与训练方法优化使精度提升,在图像、语音、自然语言处理等任务准确率和召回率显著提高。
面对现实世界,信息是以多种模态存在的,如文本、图像、音频、视频等。人类的认知过程是多模态的,我们通过视觉、听觉、触觉等多种方式感知世界。然后,上述在多模型能力方面的进展,通常都是将理解和生成任务分开处理,使用独立的模型分别应对,多模态模型的统一有助于使其更接近人类的认知模式,从而更好地理解和处理复杂的自然场景,增强人机交互体验,拓展更广泛的应用领域。相应地,多模态理解和生成的统一是当下多模态模型能力提升的重要发展方向。
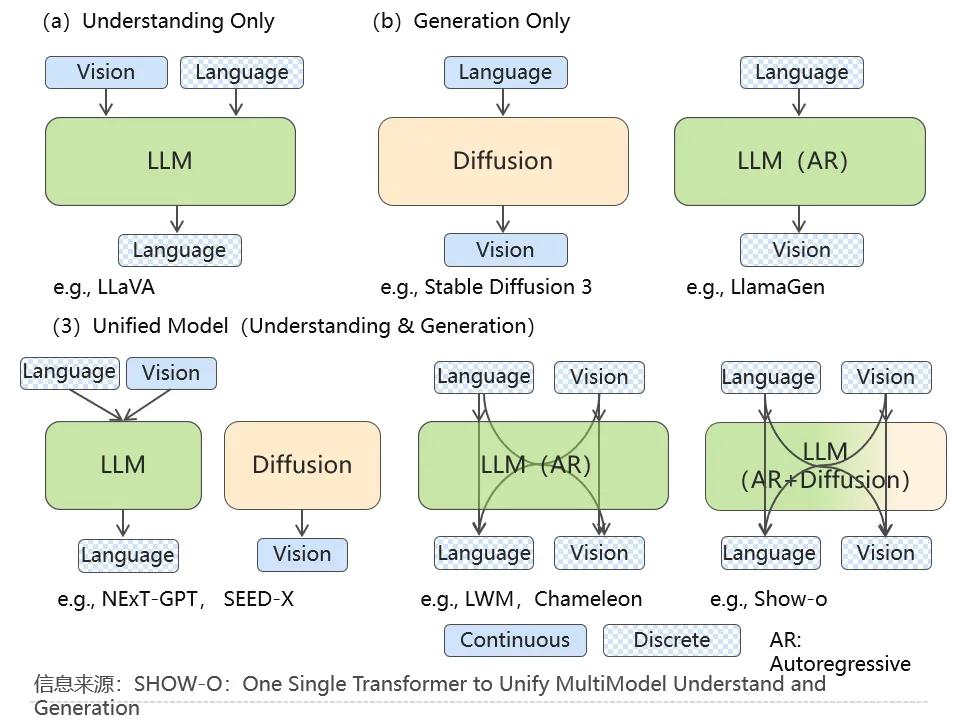
无论是上述何种思路,多模态整体上需要在如下方向进一步研究与提升,从而实现更广泛的应用落地:
技术发展
l增强跨模态理解能力
不同模态的数据(如文本、图像、音频、视频等)具有各自独特的特征和表达方式,统一发展能更好地建立起不同模态之间的关联和映射,让模型更准确、深入地理解各模态信息的内在联系和语义一致性
l提高模型的泛化能力
单一模态的模型往往只能处理特定类型的数据,在面对复杂多变的实际场景时可能表现不佳。而多模态模型的统一发展可以整合多种模态的信息,使模型能够从多个角度对事物进行理解和分析,从而提高模型的泛化能力,适应不同的应用场景和数据变化
数据管理
l促进数据融合和共享
多模态模型的统一发展需要对不同模态的数据进行融合和处理,这将推动数据的标准化和规范化,促进不同来源、不同格式的数据之间的融合和共享
l缓解数据稀缺问题
某些模态的数据可能比较稀缺或难以获取,而多模态模型的统一发展可以通过利用其他模态的数据来弥补某一模态数据的不足
应用落地
l拓展应用场景
统一的多模态模型可以打破不同模态之间的界限,为各种创新应用场景的开发提供了可能。例如,在文化娱乐领域,可以打造出具有多模态交互功能的虚拟现实(VR)或增强现实(AR)游戏,让玩家沉浸在更加丰富的虚拟世界中等
l降低应用成本
对于企业和开发者来说,使用统一的多模态模型可以减少对不同单一模态模型的开发和维护成本
l提高应用效率和质量
多模态模型的统一发展使得不同模态的数据能够在一个模型中进行协同处理,减少了数据在不同模型之间的转换和传输时间,提高了应用的效率。同时,统一模型能够更好地整合多模态信息,做出更准确、更全面的决策和判断,从而提高应用的质量和可靠性
以上观点摘录自《2025年AI产业发展十大趋势》