

随着银行风险的多元化和分散化,交易欺诈和洗钱活动在行为表现上千变万化,但是银行的风控系统通常需要在几十毫秒内做出是否拦截交易的决定,这对风控系统的准确性和即时性提出了较高的要求。
在银行风控系统中,训练交易反欺诈模型的机器学习算法按照输入数据的特征主要可以分为有监督、半监督和无监督。三种类型的机器学习算法在特征数据要求和适用场景的区别如下:
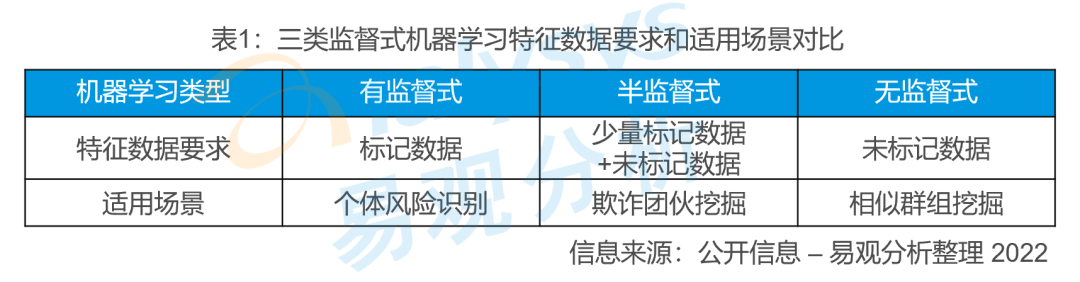
有监督式机器学习通过标记银行历史交易作为标签数据来训练交易反欺诈模型,评估交易是否规范以及判断是否需要拦截。无监督式机器学习则是自动识别一组未标记数据,即通过自动提取数据集群的特征,将不在任何集群中的样本标记为异常值,然后用已知异常值训练交易反欺诈模型,由此,系统可以识别交易数据与正常模式的任何偏差。
无监督式机器学习在一定程度上解决了银行金融风控面临的依赖专家经验和标记数据难获取的问题。但是,无监督式机器学习相对基于专家规则的风控技术而言可解释性较弱,有一定的误报率,导致银行在拦截用户后较难辨别是欺诈团伙还是行为良好的团队,而银行拦截一个优质用户的正常交易将直接影响客户体验。
易观分析认为,在风控准确性和即时性的双重要求下,半监督机器学习能融合有监督式低歧义的优势和无监督式对数据结构性特征的捕捉能力,更加适用于银行的交易风控场景,尤其是识别日渐兴起的团伙欺诈交易。
半监督式机器学习风控应用场景
半监督式机器学习的特点是将未标记数据与少量标记数据结合使用,并将事件进行关联分析,能更加有效地识别以下场景中的交易欺诈行为:
营销反欺诈
利用半监督式机器学习,即使黑产党降低同一IP下的执行交易次数,该自动化行为表现出的聚集性特征会被快速有效地识别处理。同时,半监督式机器学习识别团伙欺诈并非基于单个相似特征,而是基于在某个维度下相似属于正常用户,但多个维度下出现不正常的聚集来评判是否存在风险欺诈行为。比如,黑产党通常利用群控技术操作大量真机进行欺诈活动,如果从单个事件来看,其设备与水平面成80度角摆放,设备各项信息也并无异常,但当和其他事件进行关联时,发现所有与水平面成80度角摆放的设备,其网络信息属性一致,那么银行可以大概率断定其为风险异常事件。半监督式机器学习在反薅羊毛场景下可以保证高准确、低误杀。
团伙开卡盗刷
商业银行基于行内的开户信息、账户操作日志、银行卡交易流水等,进行数据特征的创建。再利用已获取的少量异常标签样本,将数据特征导入半监督机器学习模型,可以识别并剔除较多的正常交易,并且对判定为可疑的交易事件进行预排序和分类,再分配给不同的人工审核案件组去审查,优化专家资源配置。
利用半监督式机器学习技术,银行可以基于客户开户、网银操作等行为,在银行卡开卡阶段提前检测洗钱团伙和账户、加强识别倒卖银行卡等团伙犯罪。
虚假信贷申请
在黑中介代办的信贷申请中,欺诈者提交的若干个贷款申请都运用了一定的伪装手法,比如该群组中申请人的个人信息(名称、证件号、手机号、家庭地址、单位名称等)均不相同,且该群组中申请贷款的时间分散在周内的不同时间段内。在一般的信贷审查中,很难发现这些看似不相关的贷款申请来自同一个犯罪团伙。
但是依靠半监督式机器学习算法可以从数据在多个维度下的异常共性来挖掘出申请人的可疑共同点,比如:
该群组申请账户中大部分账户的家庭地址与征信信息中的家庭地址不一致,且部分申请中城市信息不一致;
每单申请过程中均出现登陆的GPS不唯一,甚至存在跨城市的现象;
不同申请之间都有登录同一城市的GPS信息,且登陆的均为苹果手机。
银行可以通过申请信息在多个维度下出现不正常的聚集来评判是否存在虚假信贷申请的行为。
建立风险闭环管理流程
并融合专家经验释放机器学习价值
从应用价值上看,半监督式机器学习的欺诈群组检测是从全局角度出发,基于部分已知的标记数据在高维特征空间分析用户之间的关联,并自动挖掘异常团伙。
因此,要最大化输出半监督式机器学习在风控场景下的应用价值,易观分析建议银行建立“识别—排查—处置—反馈—优化”风控闭环管理流程,形成分阶段排查、报告、迭代的体系。通过阶段性新增正负样本来调整半监督式机器学习模型参数,自动进行迭代优化,再将优化的模型进一步应用到下一阶段的预测当中,从而使半监督式机器学习算法基于风险闭环管理流程释放风控场景下的技术价值。
同时,对于风控应用场景而言,需要一定程度的可解释性来满足监管和业务的要求。易观分析建议,银行将半监督式机器学习算法与专家经验结合应用,一方面可以平衡可解释性,另一方面也能降低机器学习对于计算基础资源的成本消耗。
特征是将专家经验注入模型的重要手段,银行可以将数据特征导入半监督机器学习模型,以此来识别并剔除较多的正常交易。此外,银行也可以通过明确拦截交易的规则在一定程度上限制机器学习模型产出的结果,降低误报率。